Een top-10 en een restcategorie met 1000 gevallen hebben grote gevolgen gehad. Ex-staatssecretaris Harbers trad af omdat bepaalde misdaadcijfers niet expliciet genoemd werden in de Rapportage Vreemdelingenketen 2018. De politieke dimensie van deze kwestie is duidelijk, maar er zit ook een wetenschappelijke aan. Die is interessant, want die gaat over een probleem waar ik heel veel mee te maken heb, en met mij andere wetenschappers, maar waar nauwelijks aandacht voor is: de classificatie en presentatie van resultaten.
Verdoezeling
Het zal bij een ieder nog vers in het geheugen liggen, maar toch even kort de precieze details van de kwestie. In de Rapportage Vreemdelingenketen 2018 (hier beschikbaar), een rapport dat sinds 1987 jaarlijks wordt uitgegeven door het Ministerie van Justitie en Veiligheid, stond de volgende tabel (p. 31):

Naar aanleiding van berichtgeving in de Telegraaf bleek dat in de categorie Overige o.a. zware vergrijpen als aanranding en poging tot moord zaten. De Telegraaf noemde dit al ‘verdoezeling’, en deze betiteling werd overgenomen door Kamerleden als Geert Wilders (PVV) en Jasper van Dijk (SP). Of het bewust was gedaan of niet werd niet echt duidelijk in het Kamerdebat gisteren, maar Harbers gaf toe dat er fouten waren gemaakt en trad af.
Restcategorie
Maar wat is er nou precies misgegaan en vooral: waarom? Ook dat is niet helemaal duidelijk, maar er is wel iets over te zeggen. Het eerste wat natuurlijk opvalt aan Tabel 3.15 is hoe groot de categorie Overige is. Alleen het meestvoorkomende incident, winkeldiefstal, heeft een grotere omvang (2030 gevallen). In de categorie Overige zitten blijkbaar incidenten die minder dan 80 keer voorkomen. Dat betekent dat het er minstens 12 zijn (1000 gedeeld door 80), maar daar schieten we verder weinig mee op.
Hier hadden alarmbellen moeten afgaan. Een restcategorie is sowieso niet echt de bedoeling, maar zeker niet zo’n grote. Toch is dit niet het enige geval in de Rapportage. Neem Figuur 3.2 bijvoorbeeld:
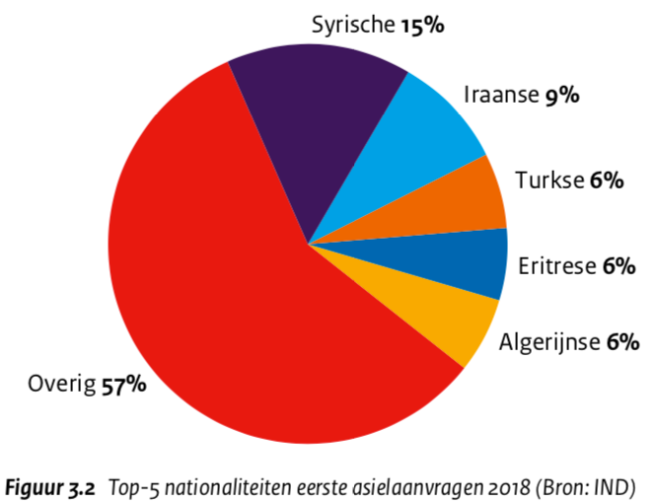
Dit is al helemaal absurd: de restcategorie is nu meer dan de helft van het totaal. Bovendien wordt er dit keer slechts een top-5 gegeven (dat gebeurt ook bij Figuur 4.1 en 4.2 overigens): waarom geen top-10? De eerlijkheid gebiedt te zeggen dat het soms beter gaat (Tabel 3.16 heeft een restcategorie van 10%), maar het lijkt een algemeen probleem.
Een interessante tabel in dit kader is ook Tabel 3.13 (p. 29). Die geeft het ‘totaal aantal door derdelanders ingediende asielaanvragen in de EU’ voor elk van de 28 landen in de EU. Geen top-10 dus, maar een volledig overzicht. Het is niet prettig leesbaar, maar wel compleet. Als het daar kan, dan vraag je je af waarom het niet ook bij de gewraakte tabel met de incidentcijfers had gekund. Het lijkt alsof men slaafs vasthoudt aan top-5 en top-10 omdat dat gebruikelijke hoeveelheden zijn. Maar je moet niet uitgaan van wat ‘normaal’ is: 5 en 10 zijn volstrekt willekeurige hoeveelheden. Je moet uitgaan van jouw data, en op basis daarvan een presentatievorm kiezen, of dat nou een top-6 is of een top-17.
Voorbeelden
Voorbij de top-10 kijken is dus al één simpele oplossing, maar er zijn er meer. Een eerste stap was al geweest om meer inzicht te geven in de categorie Overige, door te zeggen om hoeveel verschillende typen het ging. Dat wordt niet gedaan: er wordt alleen het volgende gezegd (p. 31):
“De overige 1.000 incidenten omvatten een veelheid van andere soorten misdrijven, die voorkomen variërend van enkele tientallen malen tot een enkele keer.”
Voor een wetenschappelijk artikel zou ik dit al te weinig transparant vinden. ‘Een veelheid’ is veel te vaag: het is nogal belangrijk of het inderdaad om 13 types gaat, of dat het er 1000 zijn, of iets ertussenin. Bovendien moet je voorbeelden geven van wat voor soort typen er in die categorie vallen. Ook zo had je een deel van de kritiek waarschijnlijk kunnen ondervangen.
Niveau van abstractie
Zo wordt het al iets inzichtelijker, maar het blijft wat beperkt Wat je eigenlijk moet doen als je een restcategorie hebt met zoveel gevallen is iets anders: je moet groeperen. Je moet verschillende typen incidenten bij elkaar stoppen. Dit is een bekend wetenschappelijk probleem, of eigenlijk een probleem dat je altijd hebt als je data classificeert. Je moet een betekenisvol abstractieniveau vinden.
Laat ik dat kort illustreren met een voorbeeld uit mijn eigen onderzoek. Ik deed vorig jaar onderzoek naar argumentatie in taaladvies (zie deze blogpost). In een bepaalde dataset vond ik 236 verschillende argumenten. Het zegt natuurlijk weinig als je al die gegevens los presenteert: je wil ze groeperen. Bij dat groeperen moet je proberen zoveel mogelijk inzicht te geven zonder de overzichtelijkheid te verliezen. Ik deed dat door in eerste instantie 24 argumentgroepen te onderscheiden. In mijn artikel (zie hier) presenteerde ik uiteindelijk een grafiek met de top-7 en een restcategorie. Die was nog steeds vrij groot, maar ik vertelde netjes hoeveel types daarin zitten. Het probleem was, dat je binnen die argumentgroepen ook nog kleinere groepen zou kunnen onderscheiden. Dat probleem is er altijd, maar je moet een keuze maken, een afweging tussen maximaal informatief ten opzichte van overzichtelijk.
Een hoger niveau van categorisatie had voor de Rapportage Vreemdelingenketen 2018 denk ik gescheeld. Het suffe is: zo’n categorisatie bestaat gewoon in het Wetboek van Strafrecht, zo valt te lezen op de website van het WODC (hier). Wat je natuurlijk bovendien kunt doen is eerst een indeling op een hoog abstractieniveau presenteren, om vervolgens in te zoomen, als je bepaalde categorieën wil uitlichten. Gezien de reacties was het bijvoorbeeld een goed idee geweest om de zwaardere misdrijven te benoemen. Ik denk eerlijk gezegd dat er dan helemaal niet zo’n ophef was ontstaan. Het gaat namelijk niet om zo hoeveel gevallen. Het probleem zit hem in de intransparantie.
Kortom: expres of niet, daar doe ik geen uitspraken over. Maar onhandig en onvolledig, dat vind ik wel degelijk. Het zou een goed idee zijn als de de rapportenschrijvers van het Ministerie van Justitie en Veiligheid beter zouden nadenken over welke cijfers je op wat voor manier categoriseert en visualiseert. Tabellen en taartdiagrammen, dat kan echt beter en helderder. Scheelt ook problemen.

Hi Marten,
Een dimensie vergeet je denk ik te benoemen. In het geval van asielaanvragen door landen zijn landen te categoriseren als gelijkwaardig: een land doet niet onder voor een ander land. Er is geen hiërarchie van landen, tenzij je dit benoemd. Bijvoorbeeld als je landen naar inwonersaantal categoriseert of binnen, of buiten de EU.
Echter, in het geval van misdaadcijfers zijn vergrijpen niet gelijkwaardig. Moord en doodslag zijn nu eenmaal erger dan diefstal, ook al vindt diefstal waarschijnlijk vaker plaats. Dit is waarschijnlijk ook de reden dat de schijn van verdoezeling in dit geval groot is. Deze hiërarchie van het type vergrijp zul je dus terug moeten laten komen en is onafhankelijk van het aantal vergrijpen in de categorie, tenzij ze helemaal niet voorkomen (in dat geval komen ze natuurlijk ook niet in de categorie overig).
Ik ben benieuwd hoe jouw reactie hierop is.
LikeLike
Ha Elmer, dank voor je punt. Je hebt zeker gelijk: er is een verschil tussen misdrijven wat betreft hoe zwaar het is. Een punt dat nu ondersneeuwt bijvoorbeeld is dat het eigenlijk natuurlijk ‘goed’ is dat de zware misdrijven relatief weinig voorkomen (hoewel dat me een algemene trend lijkt).
Maar je kunt voor misdaden geen absolute hiërarchie opleggen voor wat erg is en wat het ergst. Je ziet dat wel terug in de strafmaat natuurlijk, en iedereen weet dat moord erger is dan diefstal, maar de details zijn lastig. Toch los je dat volgens mij ook op door de indeling aan het houden van het Wetboek van Strafrecht (zie de link in het stuk naar WODC) en volledig te zijn. Als je volledig bent, ben je natuurlijk volledig transparant, en kunnen mensen zelf zien dat lichtere vergrijpen (althans, beschuldigingen, waar het hier om gaat) vaker voorkomen dan zwaardere.
LikeLike